The Map Task Corpus of Heritage BCMS (Bosnian/Croatian/Montenegrin/Serbian) contains 30 short audio recordings of second-generation BCMS speakers who grew up in Switzerland. The corpus was designed and developed in the courses "Corpus Linguistics" (fall semester 2019) and "BCMS as a heritage language" (spring semester 2020) at the Department of Slavonic Languages and Literatures in Zurich.
The recorded conversations are
Map Tasks:
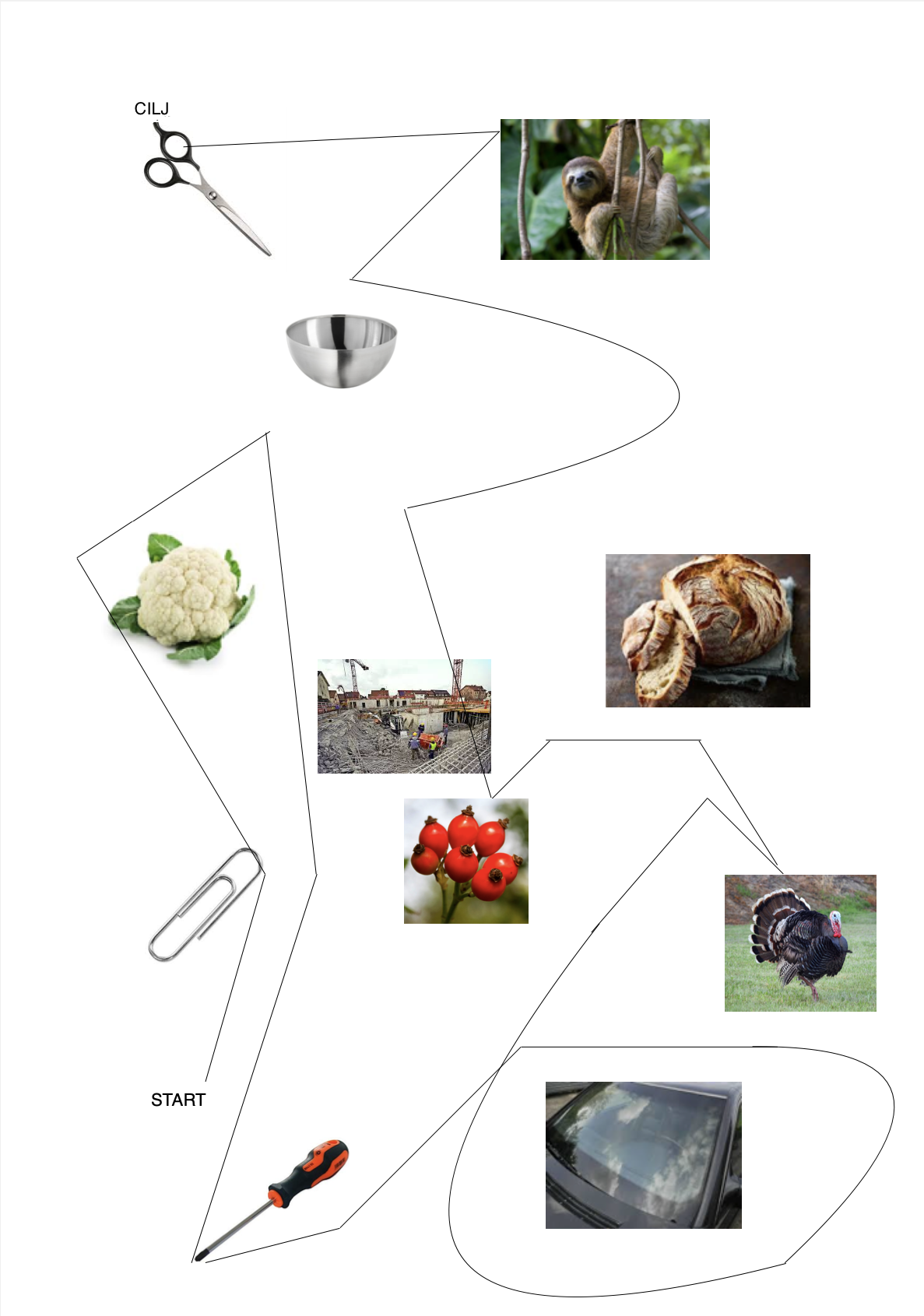
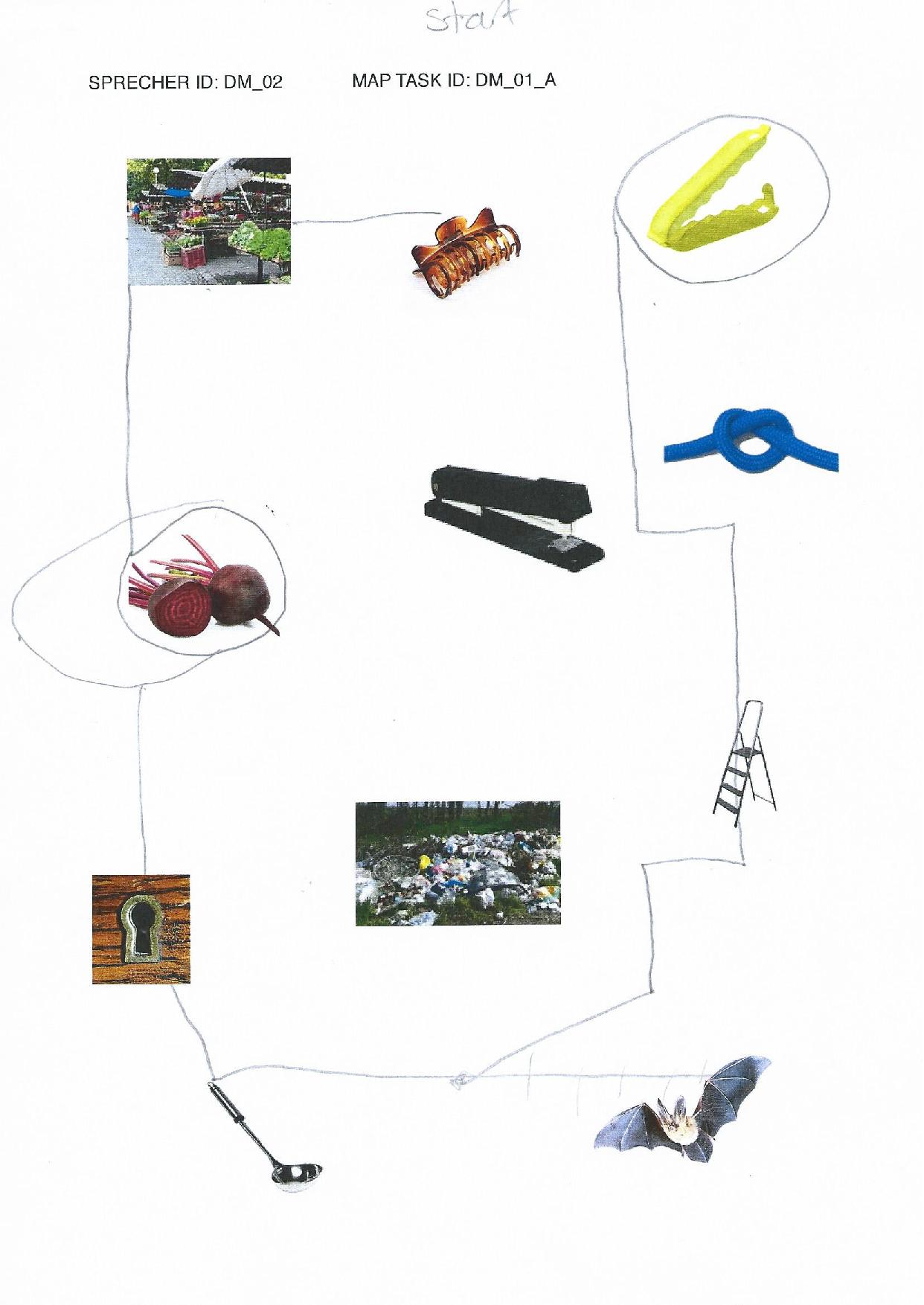
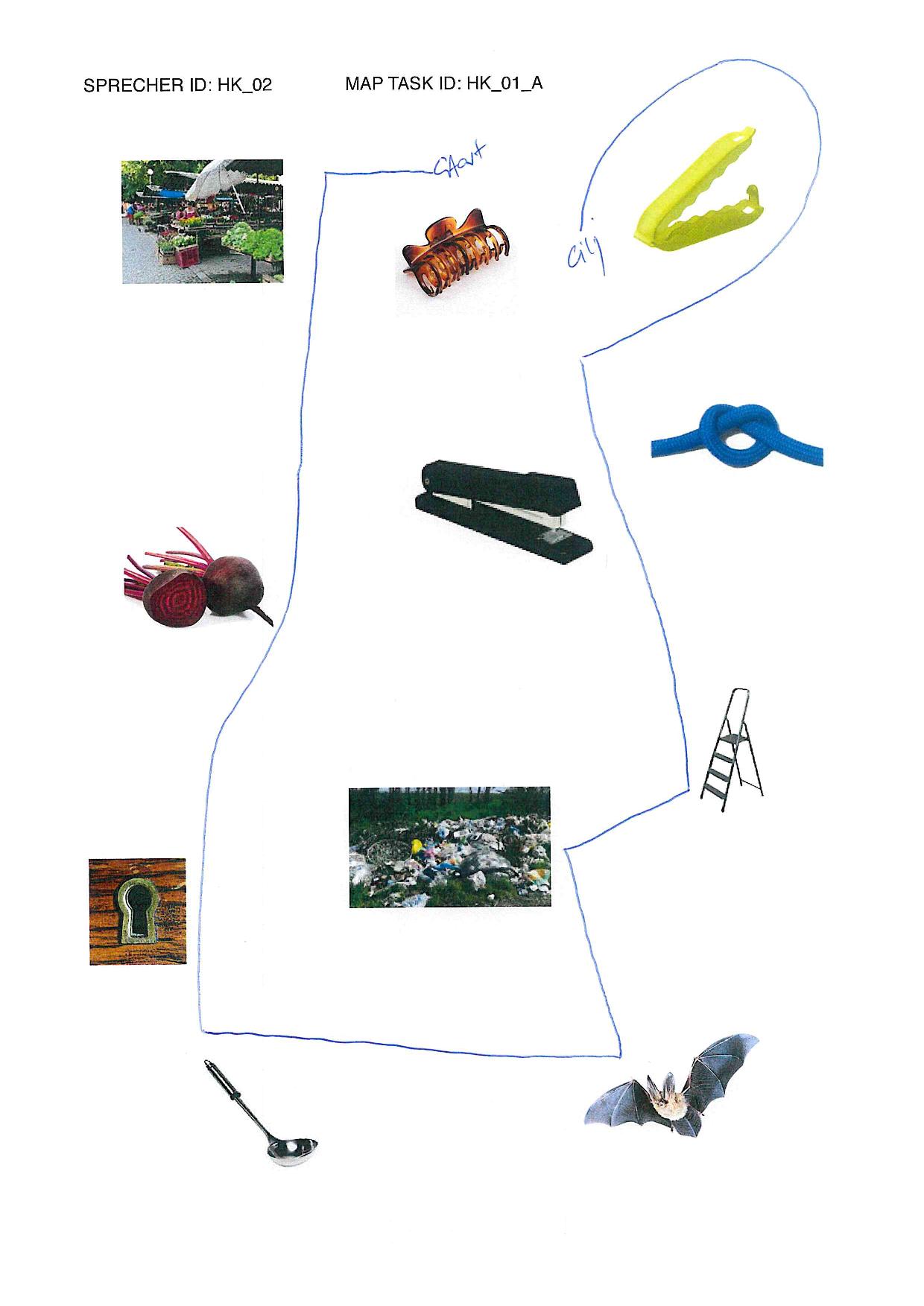
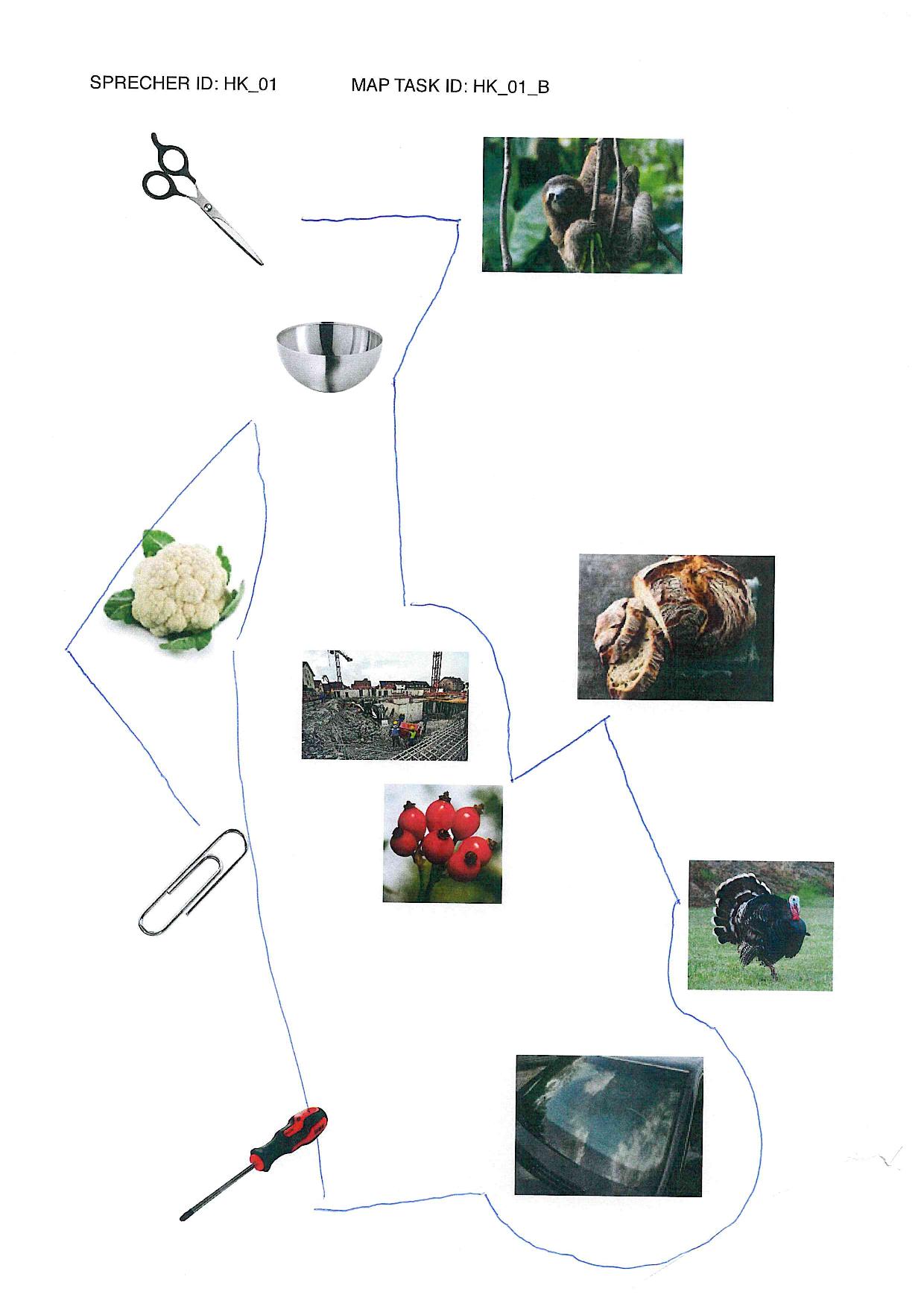
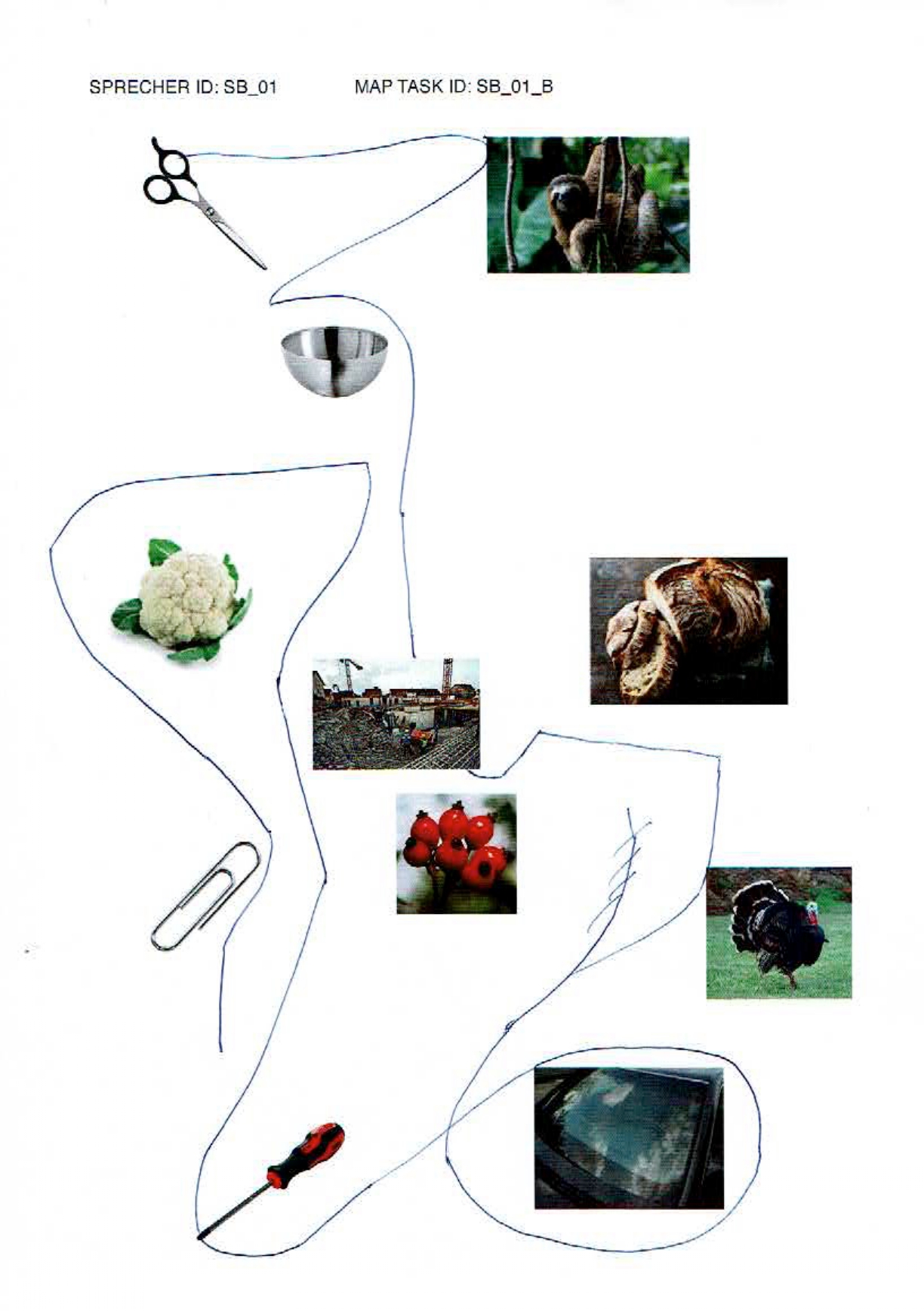
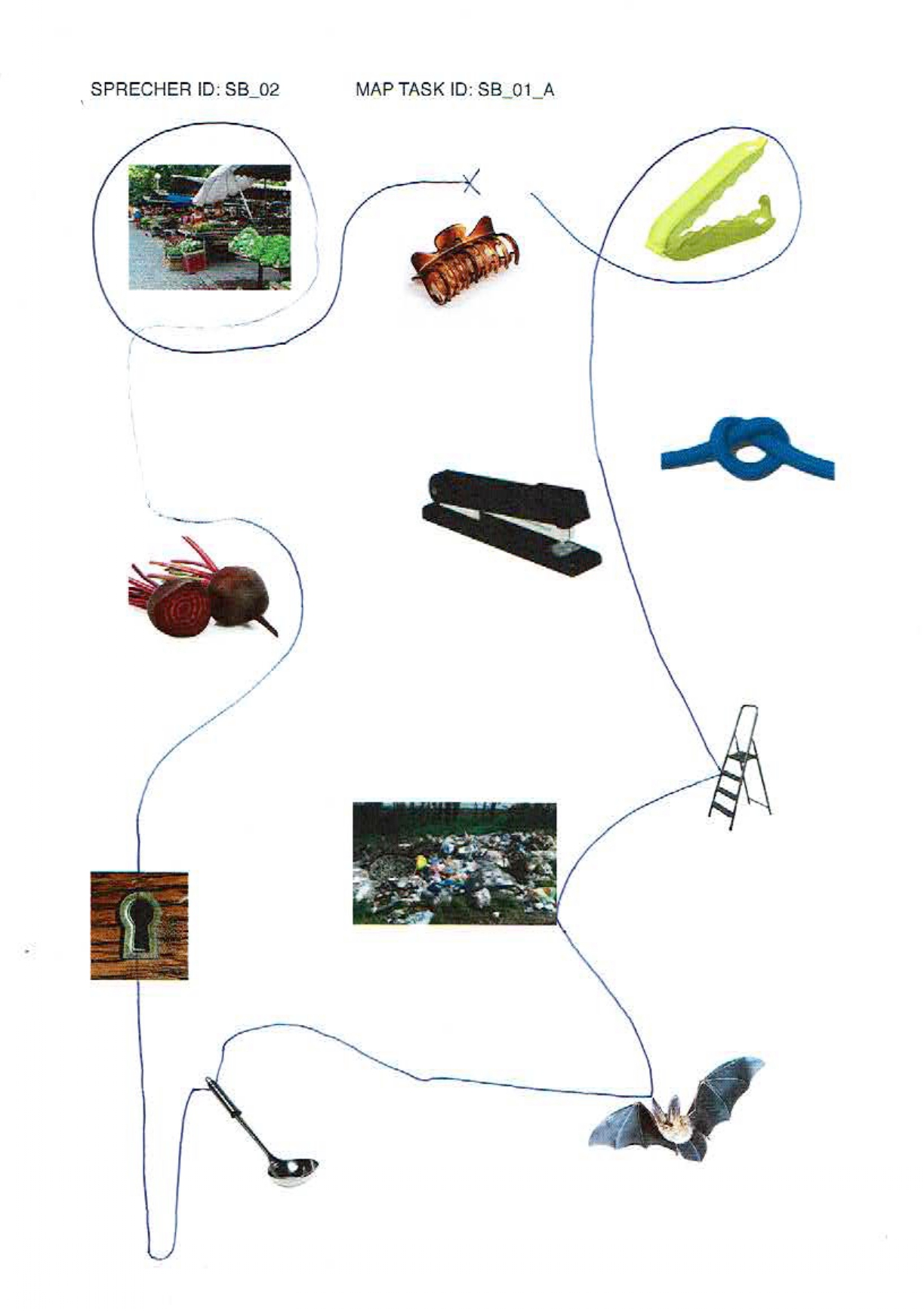
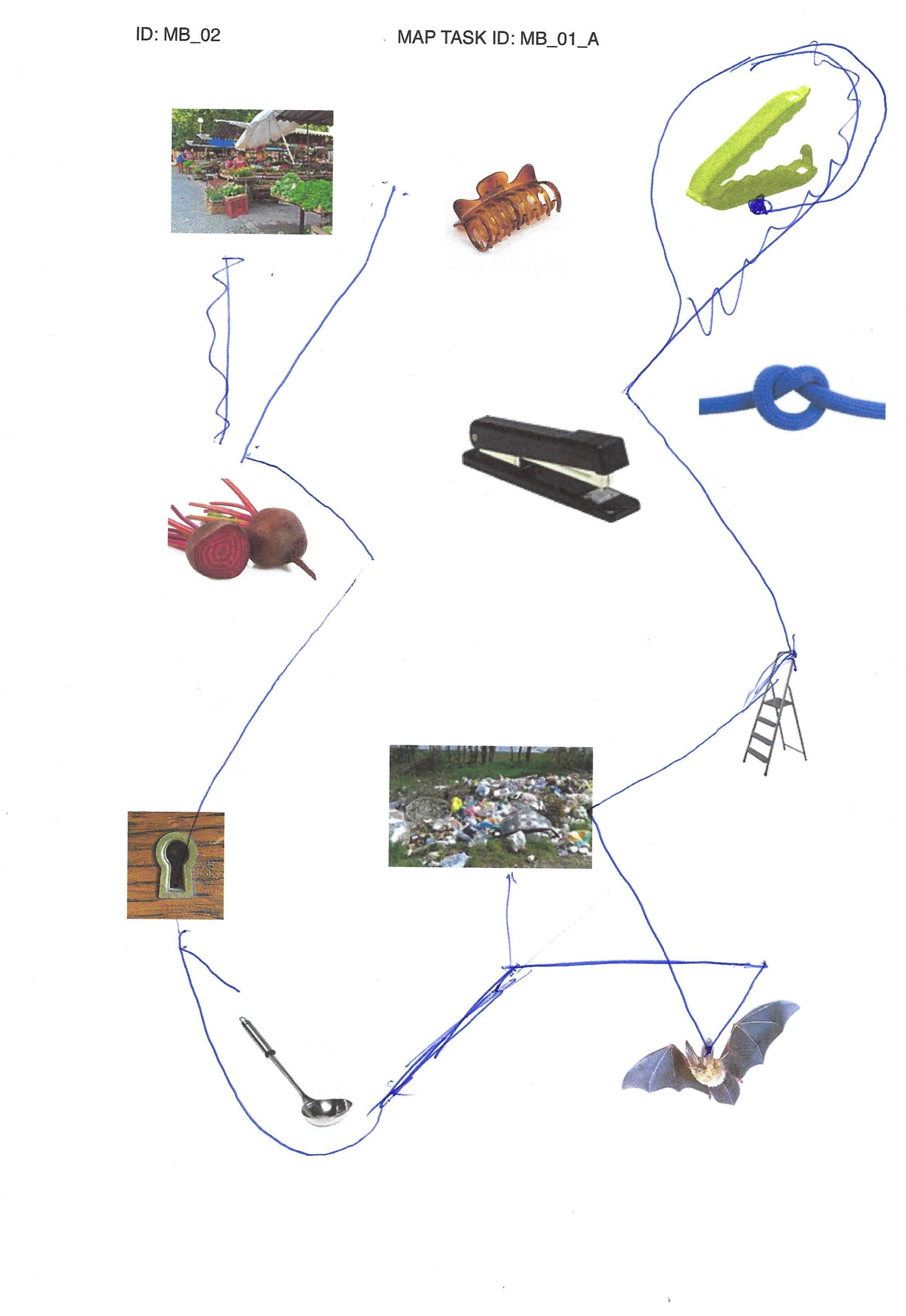
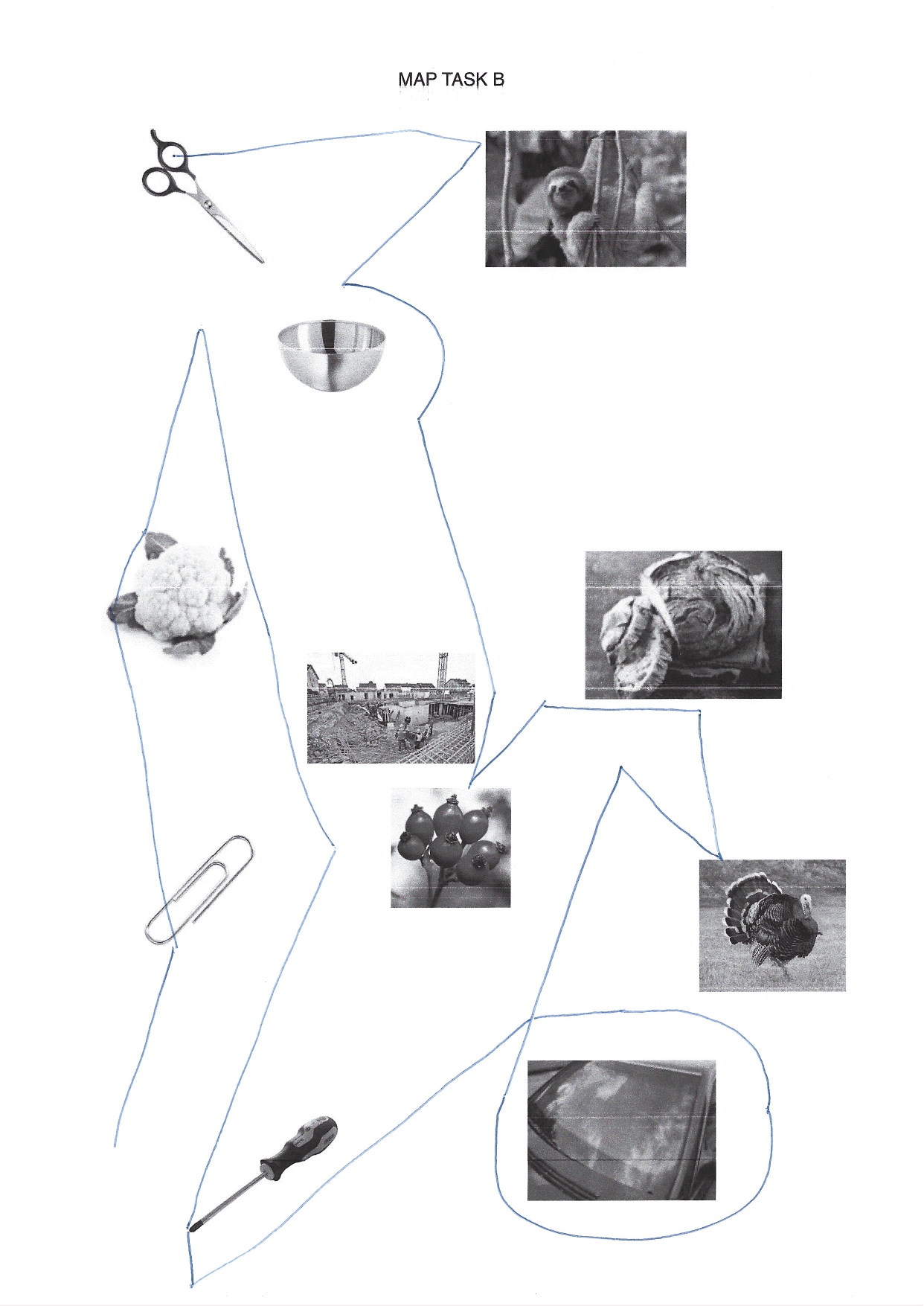
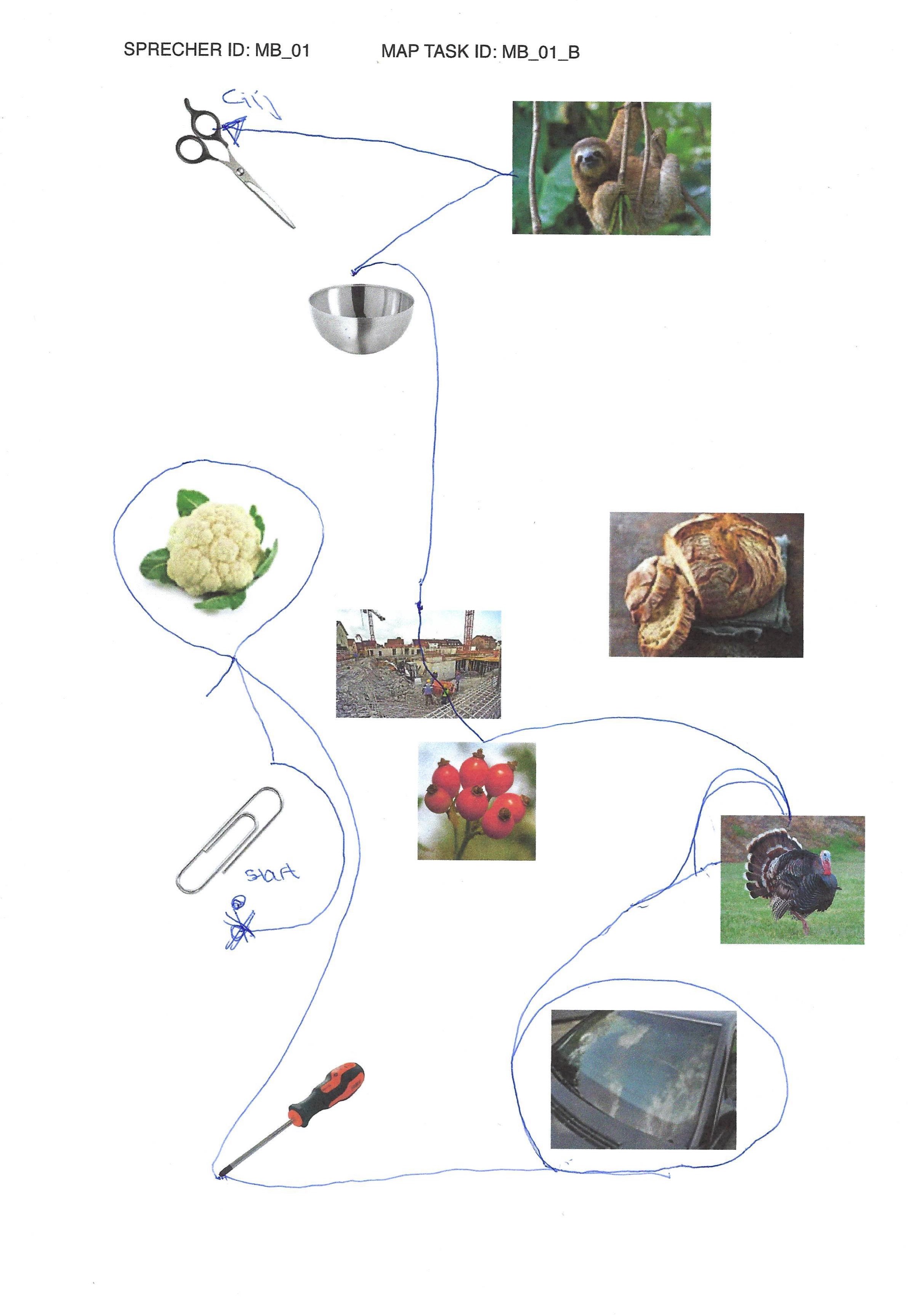
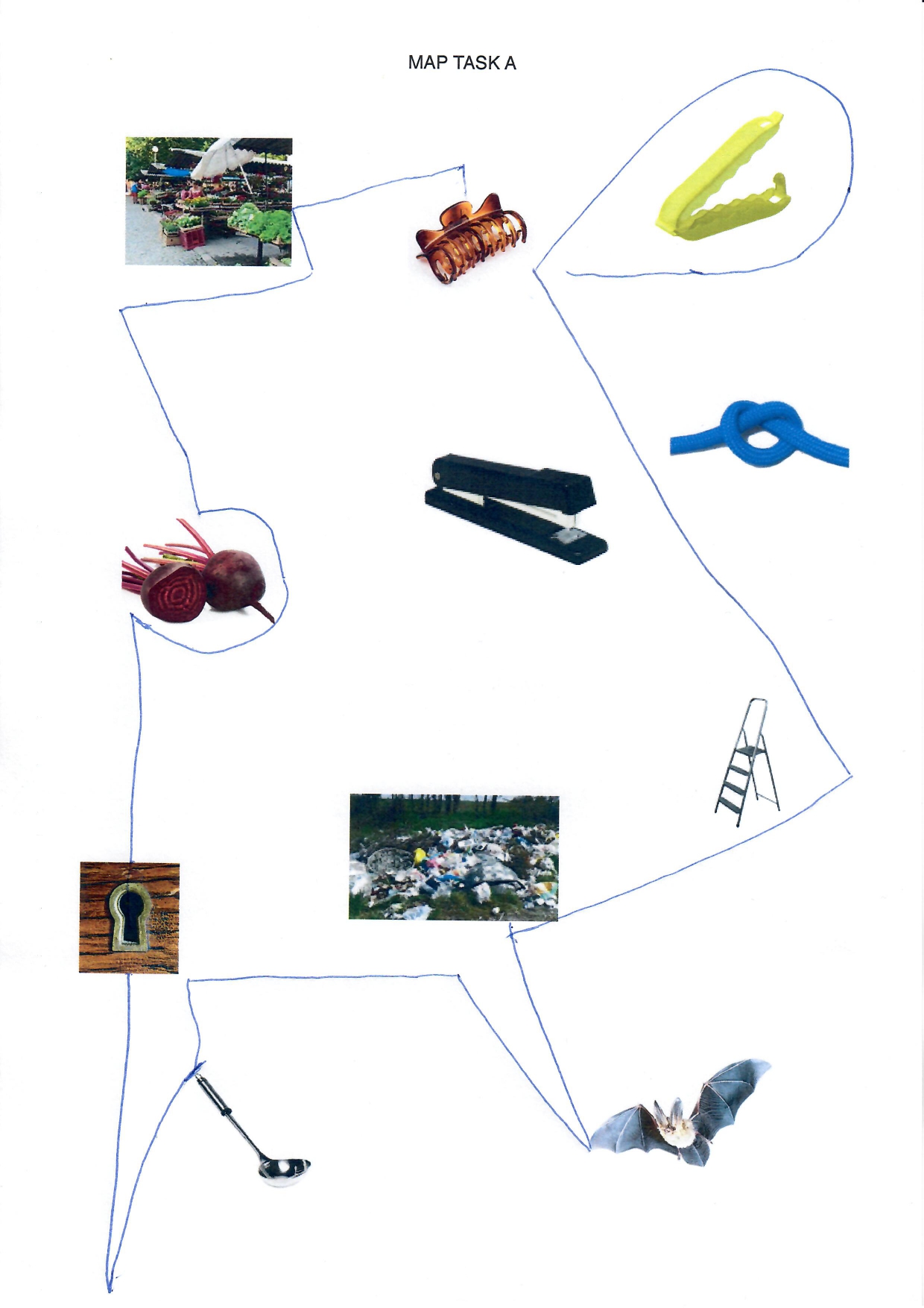
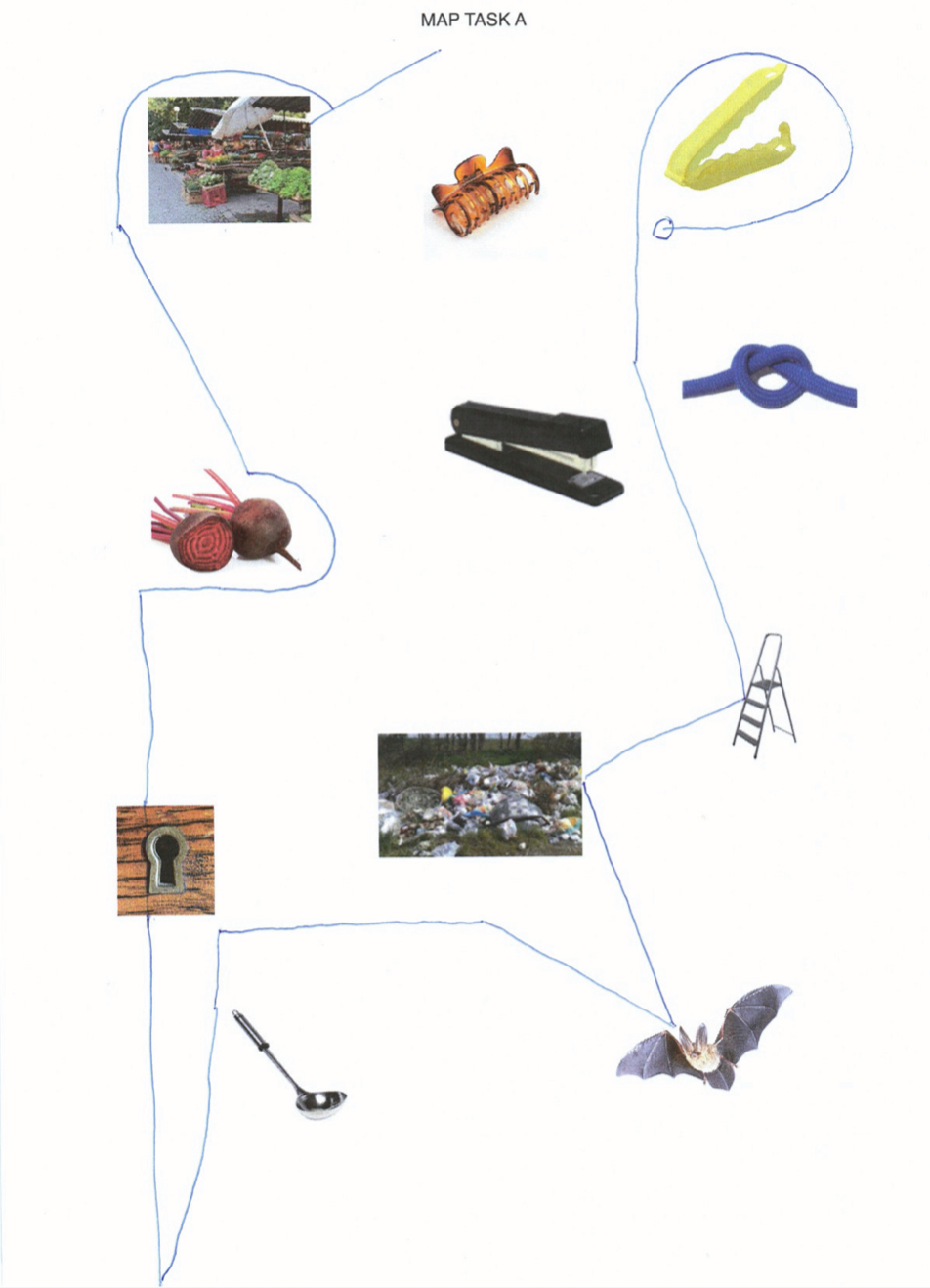
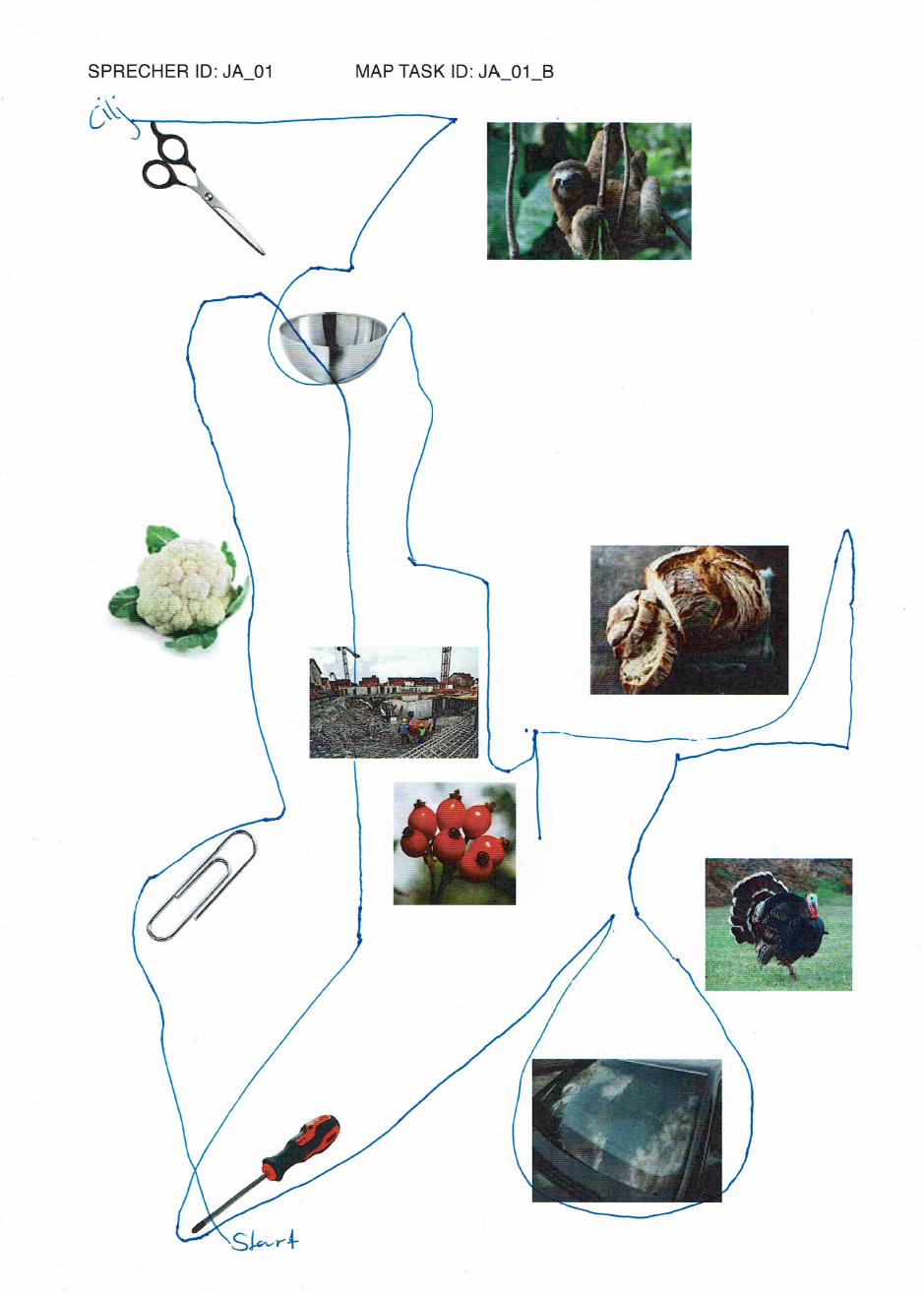
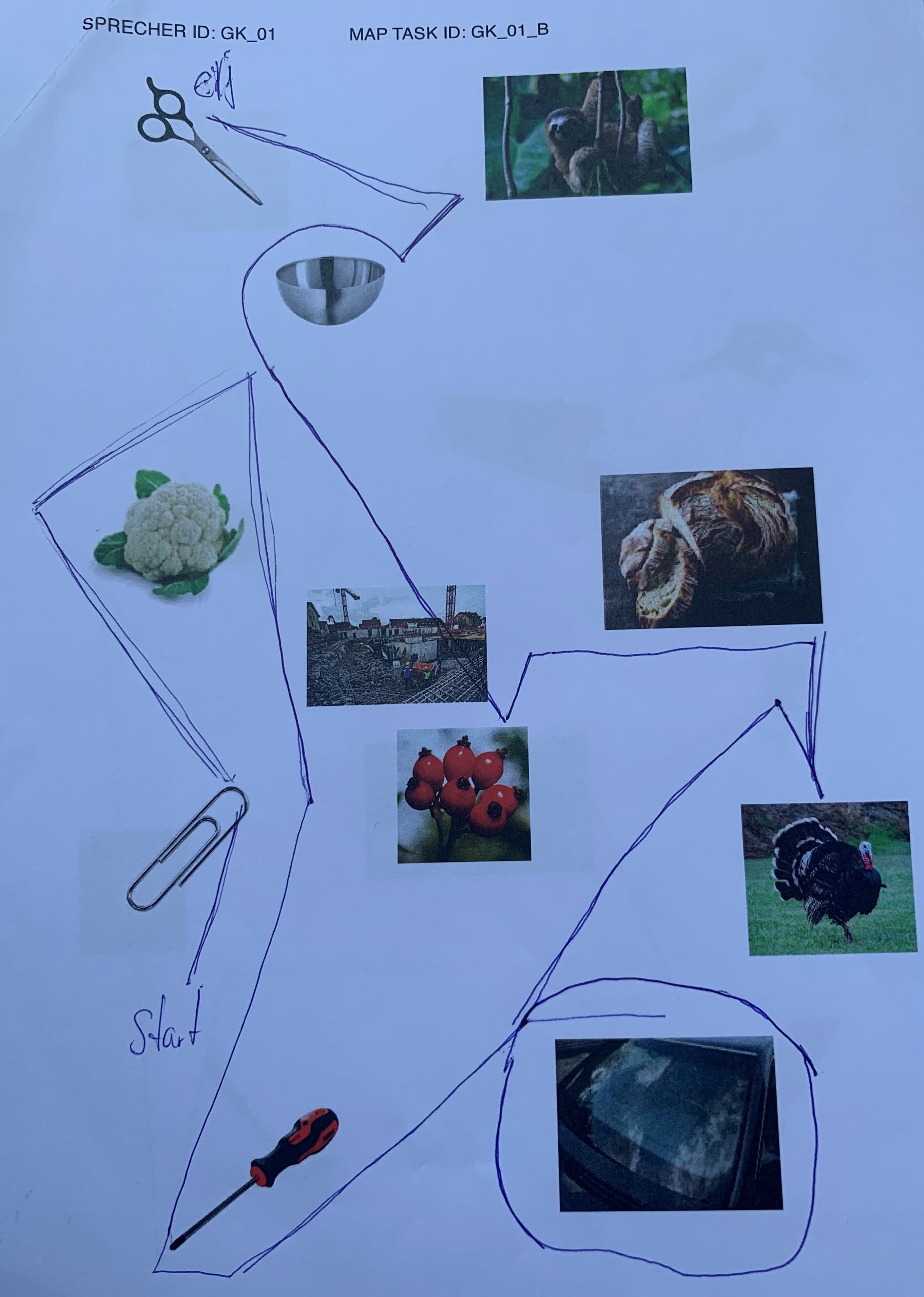
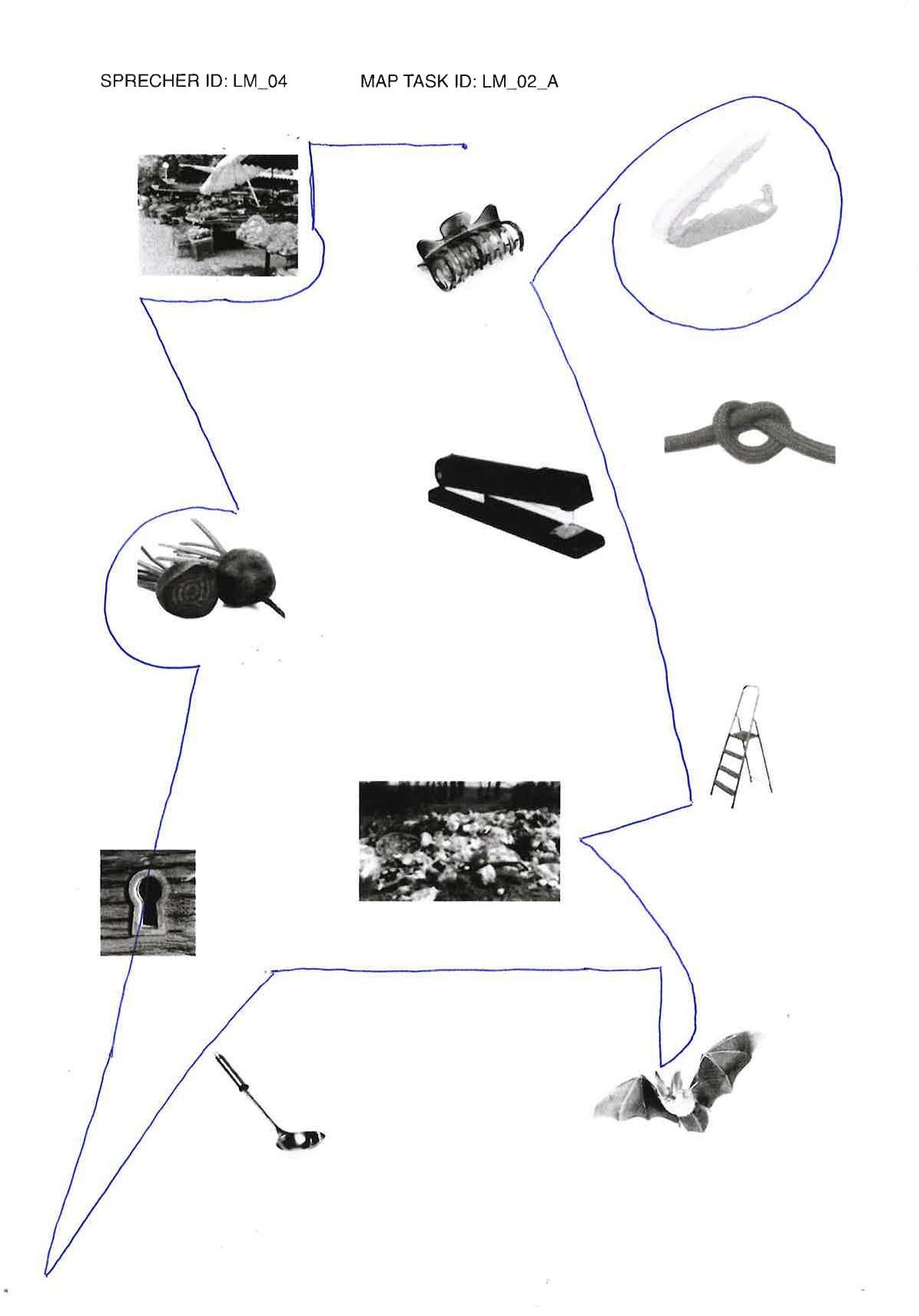
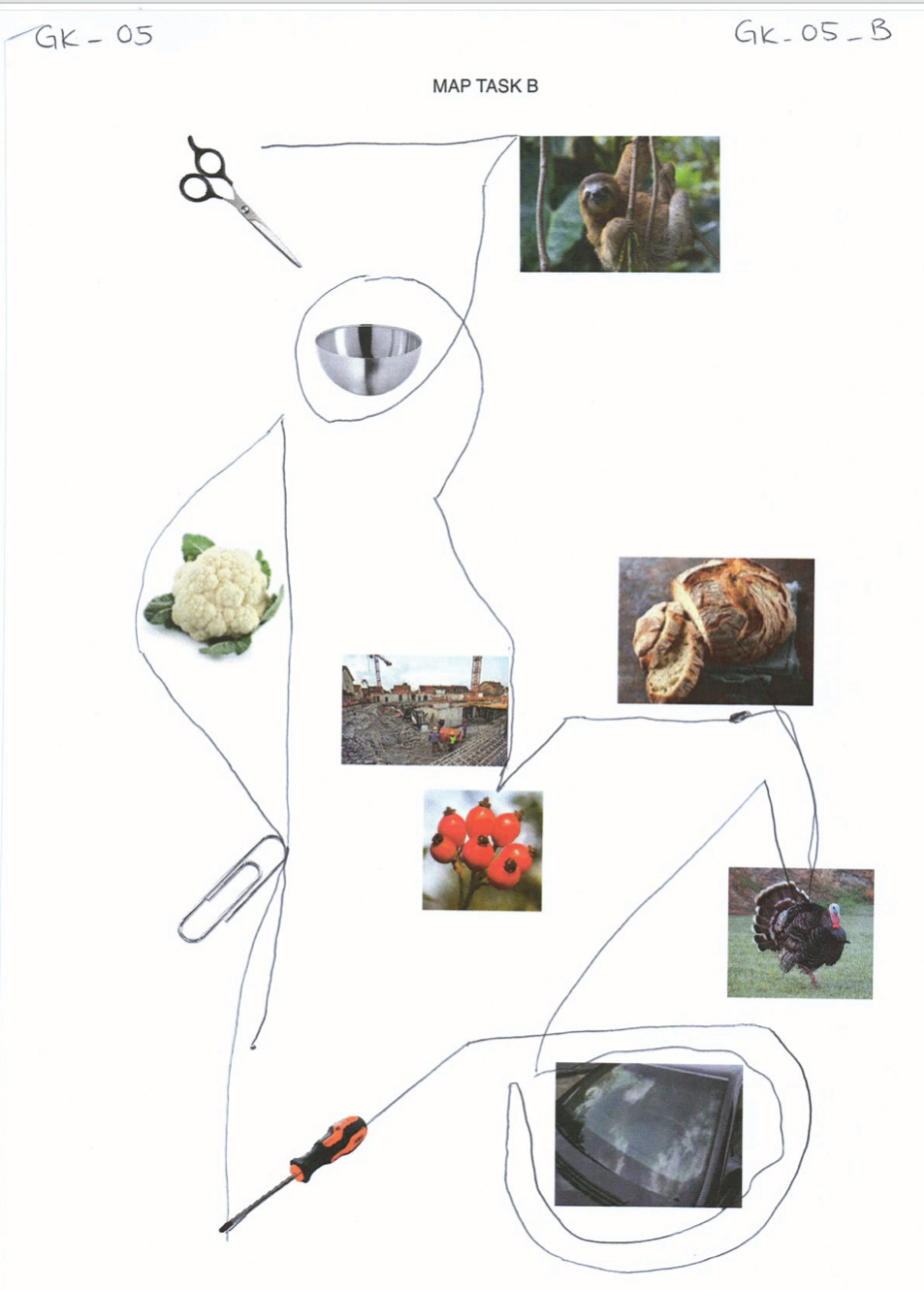
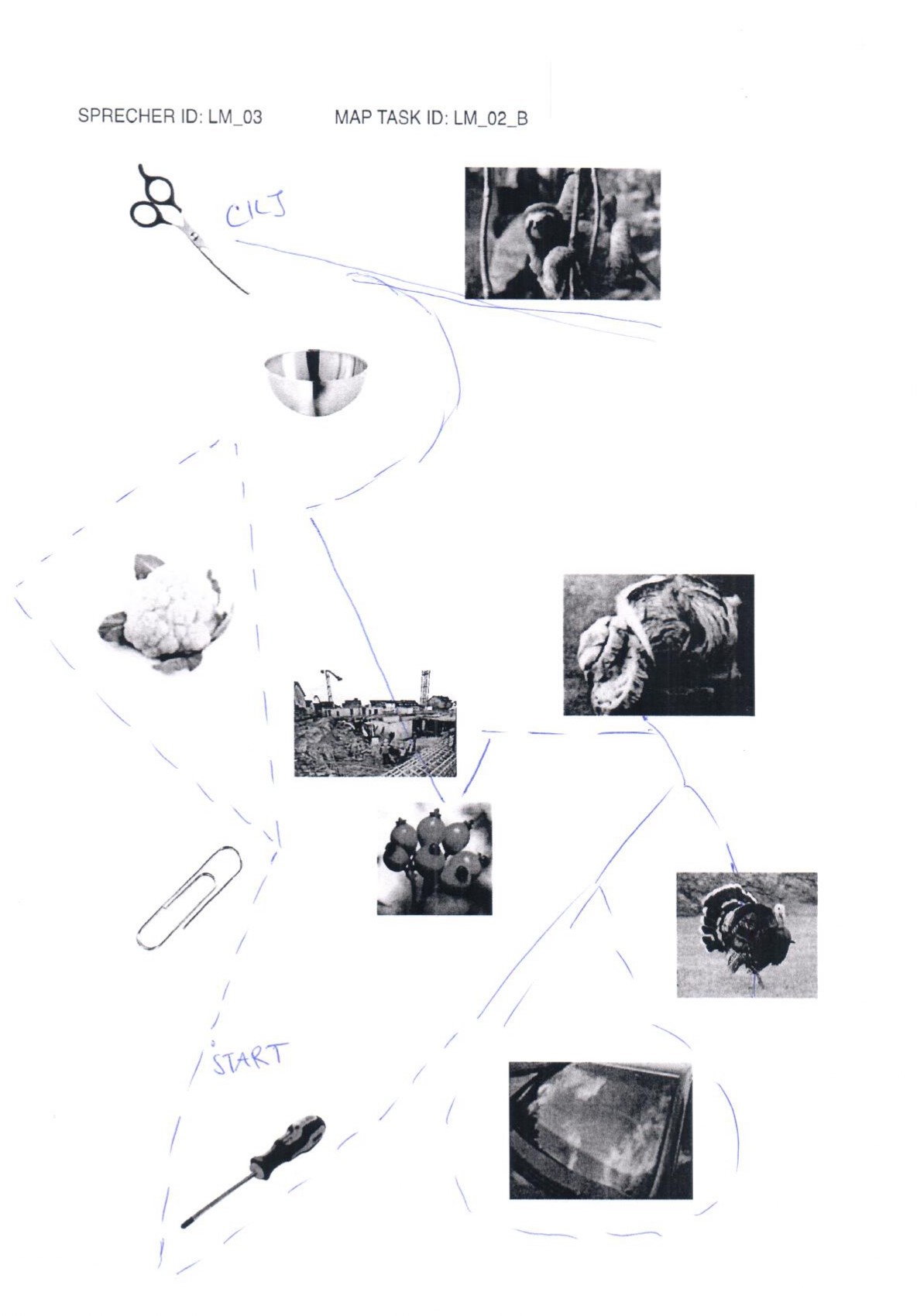
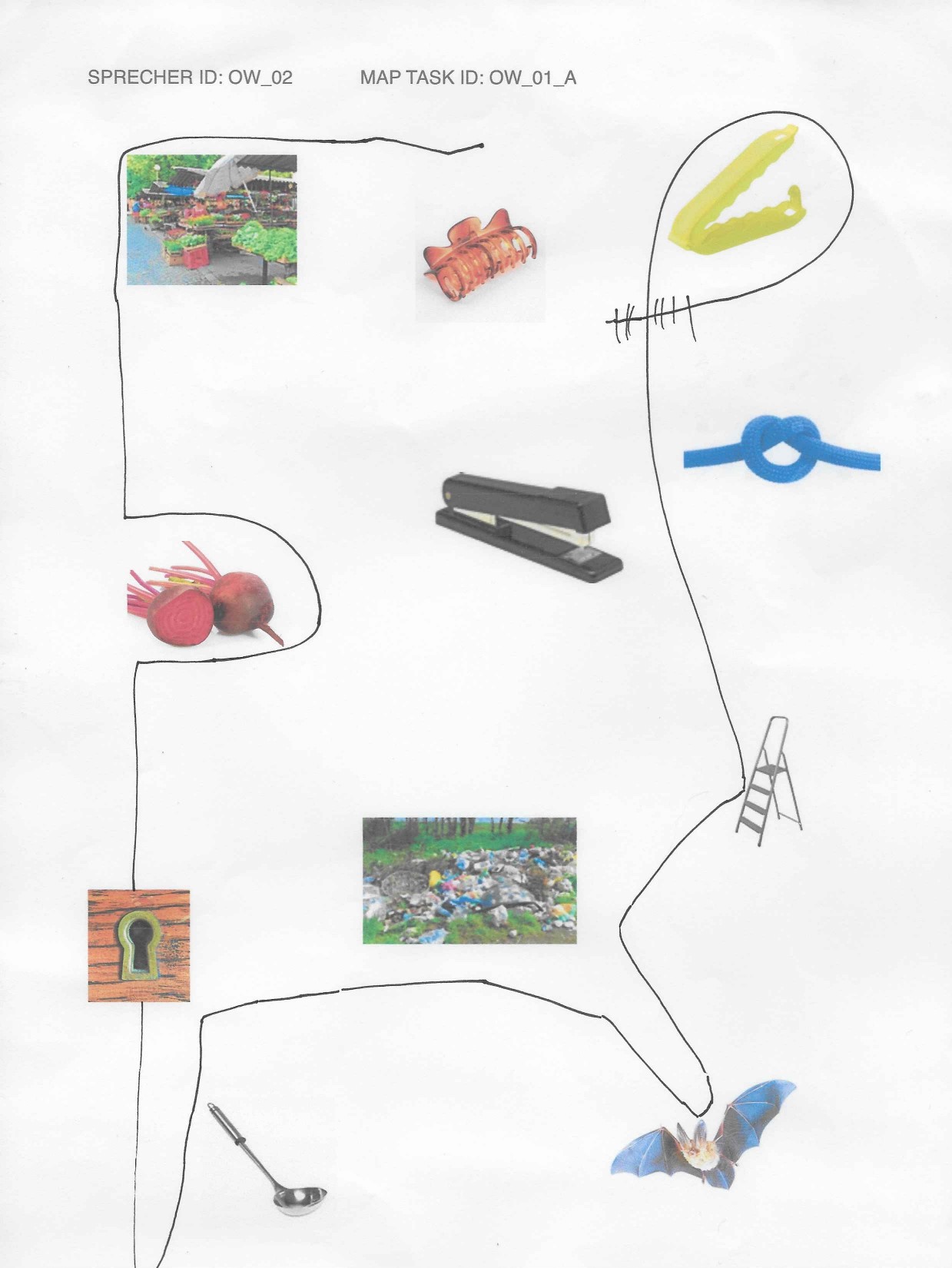
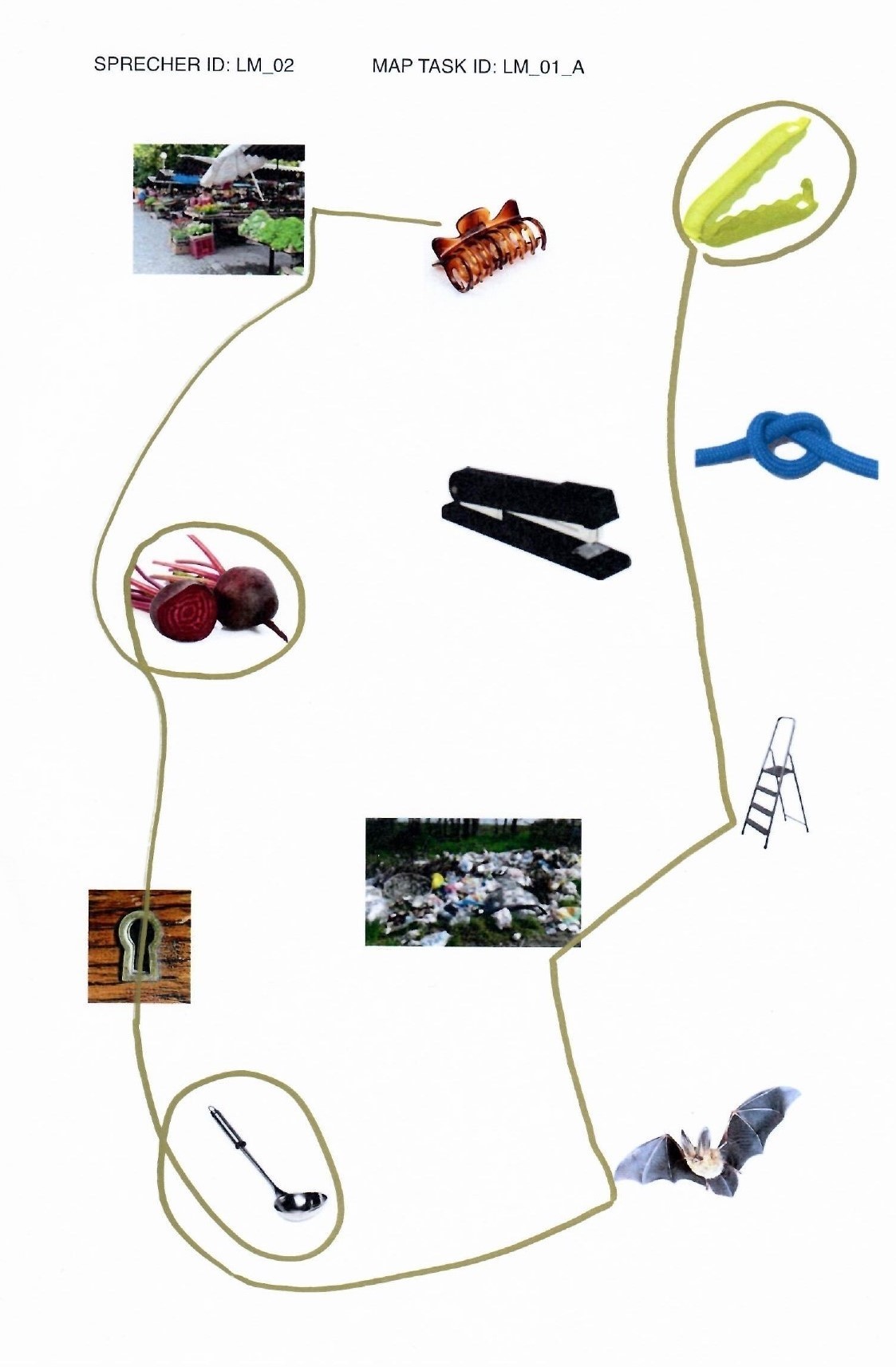
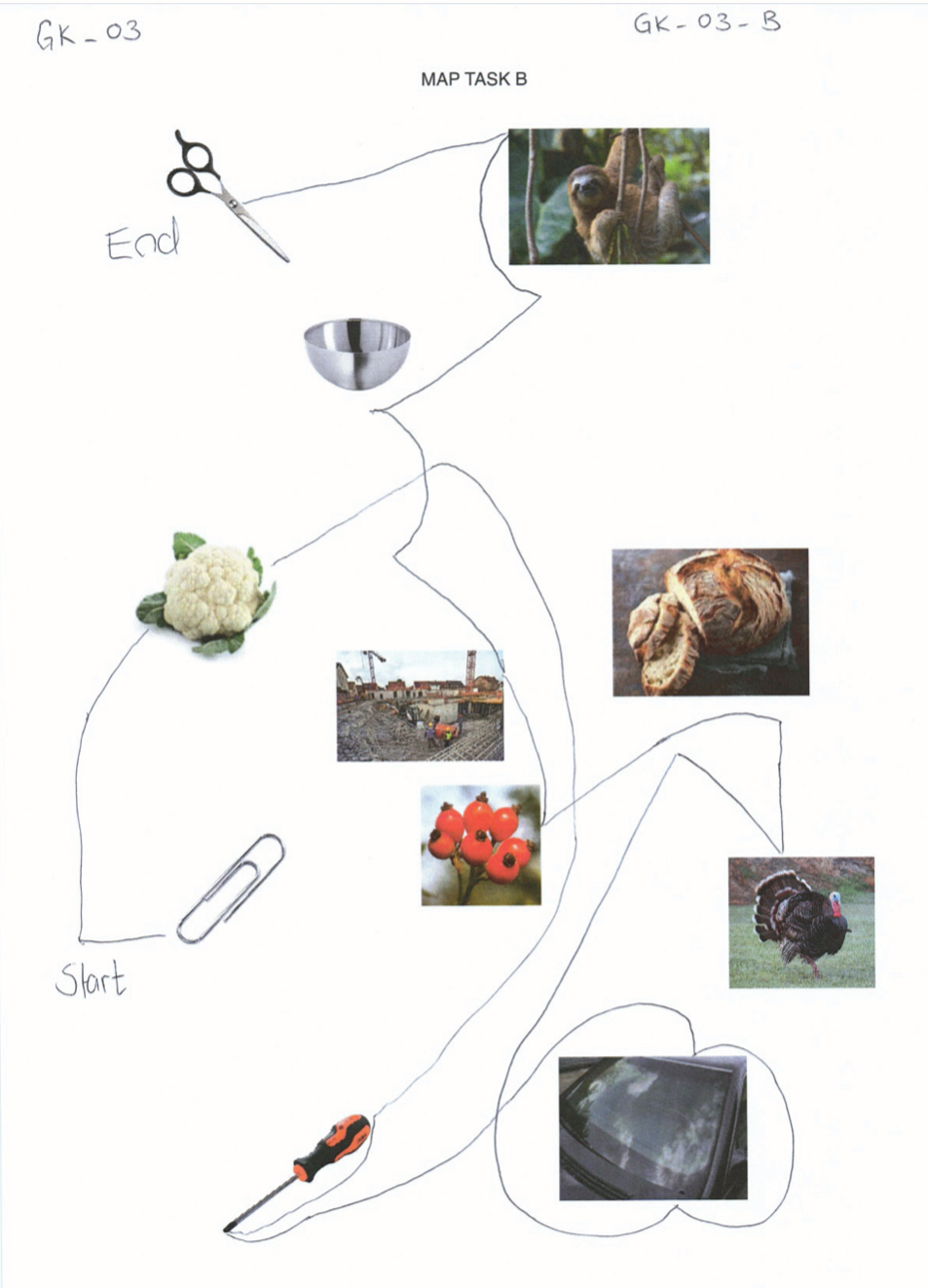
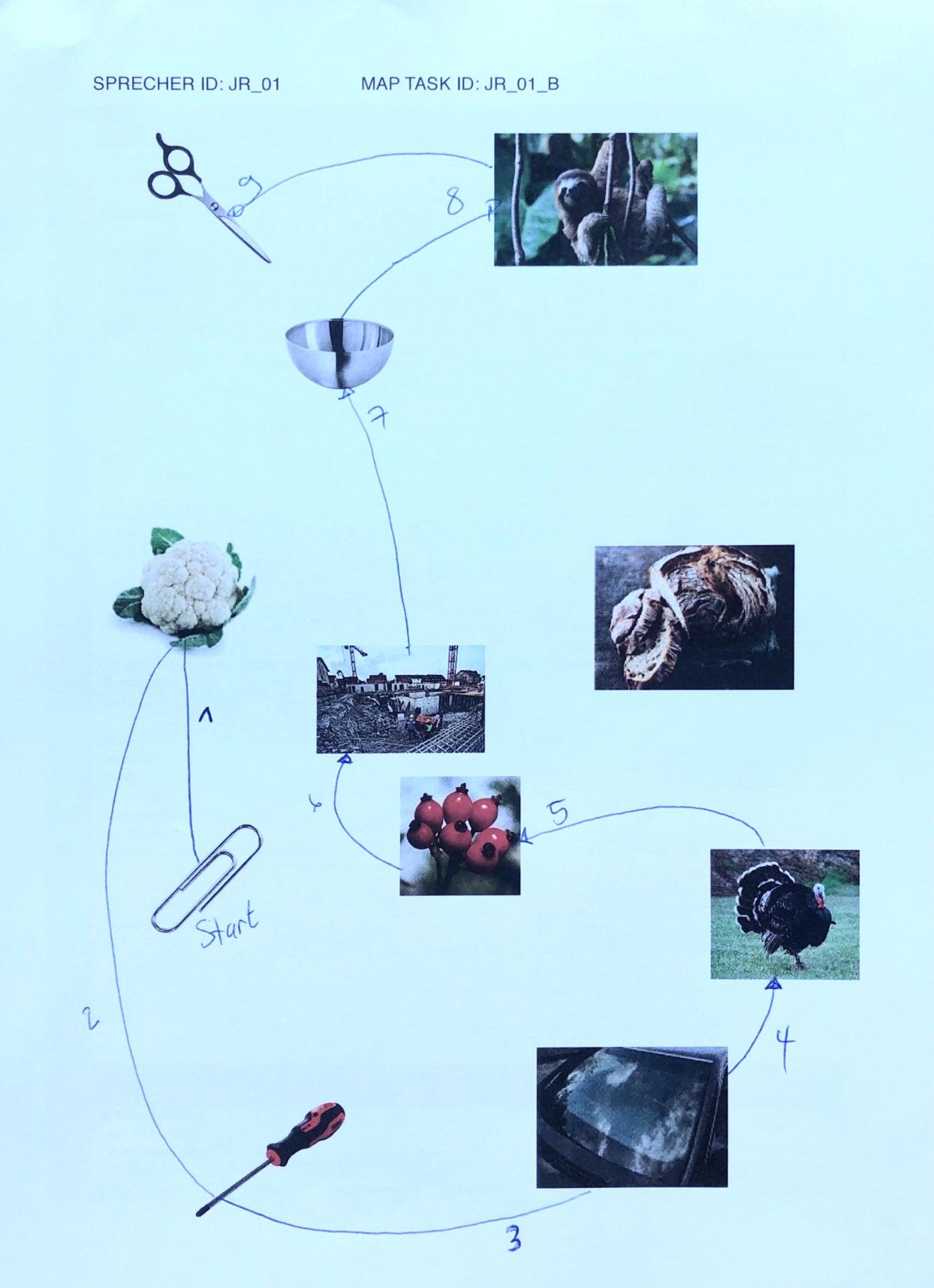
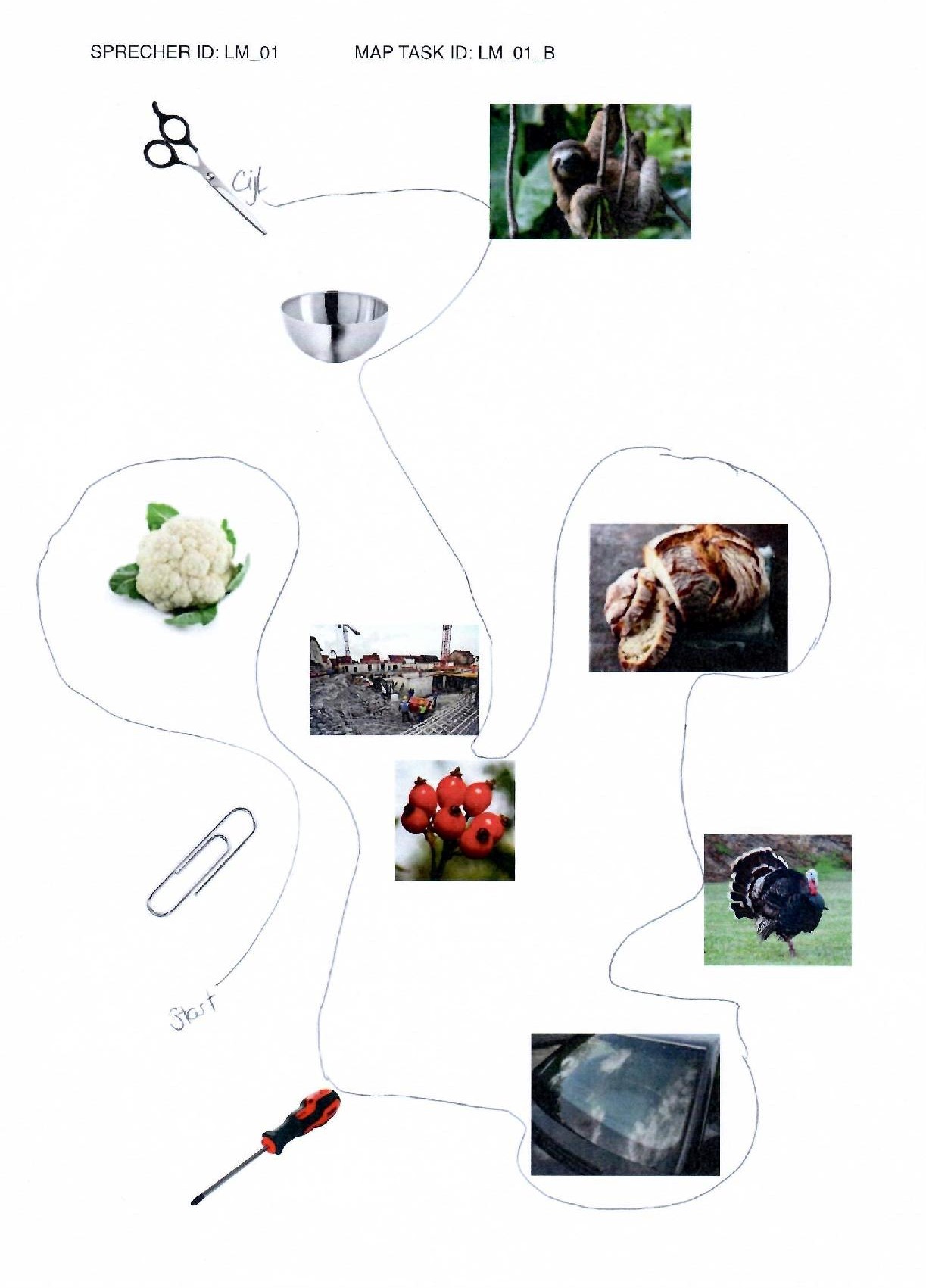
elicited conversations in which two speakers solve a collaborative task. In each case, a speaker explains to his/her counterpart how he/she should draw a line from point A to point B past various illustrations. When selecting the subjects, an attempt was made to recruit speakers from different (language) areas of former Yugoslavia.
After the recordings, metadata about the speakers was collected. A selection of the metadata can be seen in the Metadata table.
The aim of the course project was to make an initial assessment of the knowledge of one's own and "foreign" BCMS varieties with the help of short but comparable conversations.
The corpus of Map Task conversations represents a pilot study investigating the BCMS in Switzerland and serves to identify the relevant aspects of the linguistic variation as an inspiration for further research questions.
For more information about the corpus please see our paper and the corpus repository on CLARIN.SI.
Lemmenmeier-Batinić, D., Batinić, J. & Escher, A. Map Task Corpus of Heritage BCMS spoken by second-generation speakers in Switzerland. Lang Resources & Evaluation 57, 1607–1644 (2023). https://doi.org/10.1007/s10579-023-09634-7
Metadata
The data in the metadata table can be sorted, filtered and exported. The father's place of birth is marked on the folder as the speaker's place of origin. Other relevant places for each subject are marked in a separate map
places.
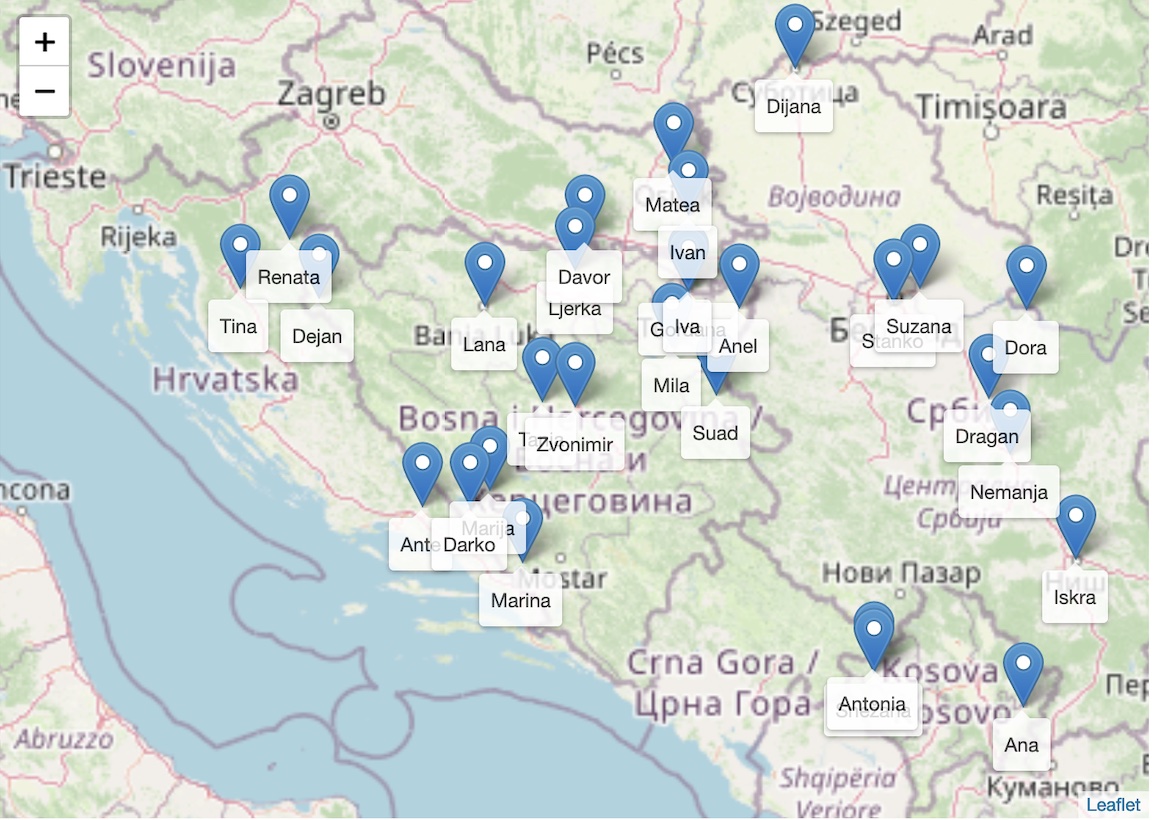
For visualising the data we used Leaflet, OpenStreetMap and DataTables.
Search
In the Search page users can search for lemma, part-of-speech, and morphosyntactic annotations.
You can also search in corpus in CLARIN.SI concordancers:
Search in NoSketch Engine
Search in KonText
Uploads
In the
Uploads page users can upload their custom annotations, share them with other users, and view shared custom annotations.
In the HTML transcripts
(transcript example), the annotated data (code-switching, breaks, non-standard language words, etc.) are accessible.
Users can also annotate the transcripts themselves according to popular categories and export the selection. A demo version of the XSLT that converts TEI files to HTML can be downloaded
here.
In addition, we provide audio files, transcripts in .xml (TEI), .fln, .flk, and textGrid format, as well as scans of solved map tasks.
Contributors
The corpus was developed in 2021/2022 by Dolores Lemmenmeier, Josip Batinić, and Anastasia Escher.
We thank all students and colleagues who contributed to the transcription, annotation and development of the corpus: Mirko Božić, Olivier-Andreas Winistörfer, Gabriela Kraljević, Linda Morf, Jovanka Antić, Samra Braković, Jovan Rosić, Dejana Jelena Milićević, Haris Kurtisi, Saša Vidić and Miro Rodin.
Image sources map task A
Market: Gimbal at Serbian Wikipedia, CC BY-SA 3.0 RS , via Wikimedia Commons; bag clip: Rotho; beetroot: kindPNG.com; hair clipper: A&A Hair Beauty; stapler: Ofrex; node: dreamstime.com (Pancaketom); key hole: Thegreenj, CC BY-SA 3.0 , via Wikimedia Commons; bat: PD-USGov, exact author unknown, Public domain, via Wikimedia Commons: ladder, garbage, soup spoon: unknown author.
Image sources map task B
Scissors: makeup.sk; sloth: Roy Toft; bowl: IKEA; cauliflower: shutterstock (Egor Rodynchenko); construction site: factumArchive; bread: Hubertus Schüler; rose hip: RGBStock.com (micromoth); turkey: dreamstime.com (Mike Neale); screwdriver: Narex; paperclip, windshield: unknown author.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}